临床试验偏倚处理方法
随机对照试验中,出现对照组不少患者换到治疗的药物(以前是安慰剂),在统计学上应该进行哪些方法处理,减少这样的偏倚?
在肿瘤学随机对照试验(RCT)中,对照组患者交叉(Crossover)或转换(Switching)至试验组治疗是一种常见的伦理设计,但会严重干扰意向性治疗(ITT)分析对长期疗效(尤其是总生存期,OS)的准确估计。为减少由此产生的偏倚,需采用专门的统计调整方法。
## 核心问题与调整必要性
当对照组患者交叉至试验组后,标准的ITT分析会将交叉患者的结果(可能因接受试验药而获益)仍归因于对照组。这会**稀释试验组的真实疗效**,导致对试验药生存获益的低估,影响卫生技术评估(HTA)和报销决策[1][3]。
## 主要统计调整方法
根据检索到的文献,处理治疗转换的统计方法主要分为以下几类:
### 1. 简单方法(通常不推荐)
* **删失法**:在交叉时间点将患者数据删失。此方法假设交叉患者与未交叉患者预后相同,通常不成立,会引入偏倚[3]。
* **排除法**:将交叉患者从分析中完全排除。同样会破坏随机化,导致选择偏倚[3]。
### 2. 复杂调整方法(推荐)
这些方法旨在估计“如果未发生交叉,患者的结局会如何”,即估计一个**反事实的生存时间**。
| 方法 | 中文名称 | 核心原理 | 关键假设 | 适用场景/备注 |
| :--- | :--- | :--- | :--- | :--- |
| **RPSFTM**[1][3][9] | 等级结构保留失效时间模型 | 假设治疗效应是加速或延缓事件发生时间。通过模型估计“治疗效应因子”,并据此回溯计算未接受试验药时的假想生存时间。 | **等级结构保留**:治疗效应在不同患者间是同质的(加速因子恒定)。无未测混杂。 | 历史较久,应用广泛。但同质治疗效应假设较强,且估计可能不稳定[1]。 |
| **IPCW**[1][3][9] | 逆概率删失加权法 | 将交叉视为一种特殊的“删失”,为未交叉的患者计算权重(逆概率),以模拟一个没有发生交叉的虚拟人群。 | **可忽略的删失**:在已测量的协变量条件下,交叉决策与潜在生存时间独立。 | 需要充分测量影响交叉决策和预后的所有协变量。权重不稳定时可能导致极端值。 |
| **TSE**[1] | 两阶段估计法 | **第一阶段**:在对照组内,用加速失效时间(AFT)模型估计交叉对进展后生存期(PPS)的影响。<br>**第二阶段**:利用该效应估计值,调整交叉患者的PPS,并与无进展生存期(TTP)相加得到调整后的OS。 | **无未测混杂**:第一阶段模型包含了所有同时影响交叉决策和PPS的协变量(X₁)。 | 直观,直接针对OS的组成部分建模。对模型设定和协变量测量要求高。 |
### 3. 结合外部数据的增强方法
当试验内非交叉患者样本量小、交叉率高时,上述方法估计值的不确定性(方差)会很大[1]。**增强两阶段估计法(ATSE)** 被提出以解决此问题[1]。
* **原理**:将试验中**未交叉的对照组患者**与**外部真实世界数据(RWD)或历史试验的对照组患者**合并,形成一个“混合非交叉对照组”,用于更精确地估计第一阶段模型中的治疗效应。
* **优势**:在外部数据无混杂的条件下,可减少偏倚并提高估计精度[1]。
* **关键假设**:
1. 无未测混杂(同TSE)。
2. **数据可交换性**:在调整所有观测协变量(X₁ 和 X₂)后,试验患者与外部数据患者的预后是可交换的。X₂ 指所有影响预后和试验参与状态的协变量[1]。
* **衰减因子(c)**:ATSE引入衰减因子控制外部数据的借用强度(c值越大,借用越少),需进行敏感性分析(如c=1, 4, 8)[1]。
**以下示意图阐释了意向性分析(ITT)与符合方案分析(PP)在处理受试者交叉或脱落时的差异,以及不同临床试验类型的统计判定界值:**
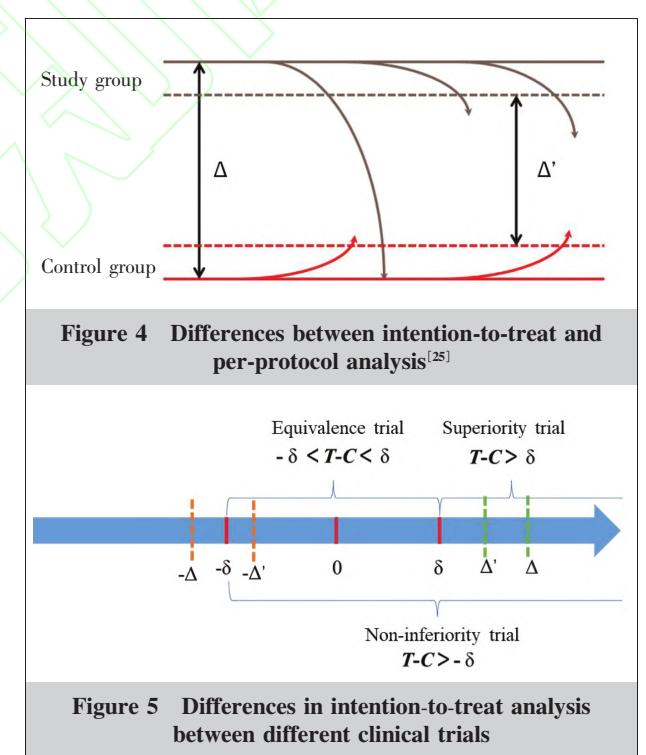
*Figure: 临床试验设计示意图,展示了意向性分析(ITT)与符合方案分析(PP)的区别,以及等效性、优效性和非劣效性试验的统计判定界值。*
## 方法选择与实施建议
1. **预先规划**:在试验方案和统计分析计划(SAP)中预先明确是否允许交叉及将采用何种调整方法,并说明理由[3][10]。
2. **全面收集数据**:详细记录所有患者的**交叉时间、交叉后治疗**,以及可能影响交叉决策和预后的**基线及时间依赖性协变量**(如疾病进展时的状态、PS评分、生物标志物等)[3]。
3. **分析数据集**:主要疗效分析(如OS)应基于**意向性治疗(ITT)原则**,所有随机化患者均纳入最初分配组分析[4][6][8]。调整方法是在ITT框架下对数据进行校正,而非改变分析集。
4. **报告与敏感性分析**:
* 详细报告交叉的程度、模式和原因[3]。
* 报告调整前后的结果对比(如风险比HR和限制性平均生存时间差dRMST)[1]。
* 必须进行广泛的**敏感性分析**,以评估关键假设(如无未测混杂、模型规格)不成立时结果的稳健性[1][3][5]。这包括使用不同的调整方法(RPSFTM, IPCW, TSE)、不同的模型参数、以及不同的外部数据借用强度(对于ATSE)进行比较。
5. **合理解释**:明确调整后的估计所对应的**估计量**(例如,“试验治疗 vs. 对照治疗,假设对照组患者未在进展后交叉”),并在讨论中承认相关假设的局限性[3]。
## 总结
处理RCT中的治疗转换偏倚,首选基于模型的调整方法(如RPSFTM、IPCW、TSE),而非简单的删失或排除。当试验内部数据有限时,可考虑使用ATSE等结合外部数据的方法以提高精度,但必须谨慎评估并报告数据可交换性等强假设。所有处理均需预先规划、透明报告,并辅以充分的敏感性分析。
---
*本分析基于检索到的临床研究方法学文献,旨在为临床研究设计与统计分析提供参考。具体试验中的方法选择和应用需结合研究目的、数据特点和监管要求,由专业统计学家与临床专家共同决定。*
RPSFTM方法,能给出SAS和R的代码吗
根据检索到的文献,**等级结构保留失效时间模型(RPSFTM)** 是处理随机对照试验中治疗转换偏倚的核心统计方法之一[1]。其核心原理是通过估计一个**加速因子(Acceleration Factor, AF)**,来反推如果患者从未接受试验治疗时的“反事实”生存时间。
## RPSFTM方法核心原理与步骤
1. **模型假设**:试验治疗对生存时间的影响是**同质的**,即对所有患者产生相同比例的加速或延缓效应(“共同治疗效应”假设),且效应在开始治疗时立即生效,停药时立即消失[1]。
2. **结构模型**:对于第 *i* 名患者,其观察到的总生存时间 *Tᵢ* 被分割为接受对照治疗的时间 *T_Cᵢ* 和接受试验治疗的时间 *T_Eᵢ*。假设的反事实生存时间 *Uᵢ*(即如果该患者始终只接受对照治疗的时间)由以下公式给出:
$$U_i = T_{Ci} + \frac{T_{Ei}}{AF}$$
其中,*AF* 即为待估计的加速因子。*AF* > 1 表示试验治疗延长生存,*AF* < 1 表示缩短生存[1]。
3. **估计过程(G-估计)**:通过网格搜索等方法,寻找一个 *AF* 值,使得基于反事实时间 *Uᵢ* 计算的两组(试验组 vs. 对照组)**对数秩检验(Log-rank test)的统计量接近于零**。这意味着在消除了治疗转换的影响后,两组生存曲线无统计学差异,符合随机化初期的平衡状态[1]。
4. **结果呈现**:报告估计的 *AF* 及其置信区间,并绘制基于反事实生存时间 *Uᵢ* 的 Kaplan-Meier 曲线进行比较[1]。
## RPSFTM的SAS与R语言实现
以下提供基于公开文献和统计软件包的核心代码框架。**请注意,实际应用需根据具体试验数据结构进行调整和验证。**
### SAS实现
SAS中可通过 `PROC IML`(矩阵运算)或宏编程实现网格搜索和G-估计。一个高度简化的概念性框架如下:
```sas
/* 步骤1:准备数据,需包含变量:
id: 患者ID
arm: 随机分组 (0=对照组, 1=试验组)
t_obs: 观察到的生存时间
event: 事件指示符 (1=事件发生,0=删失)
t_switch: 从对照组交叉到试验组的时间(若无交叉,则为缺失值或大于t_obs)
t_exp: 接受试验治疗的时间 (需根据t_switch和t_obs计算)
t_ctrl: 接受对照治疗的时间 (t_obs - t_exp)
*/
/* 步骤2:定义计算对数秩统计量的宏函数 */
%macro logrank_stat(af);
data temp;
set your_data;
/* 计算反事实生存时间 U */
if t_exp > 0 then U = t_ctrl + t_exp / ⁡
else U = t_obs;
/* 处理删失:通常需要重新删失,此处简化 */
run;
/* 使用PROC LIFETEST计算对数秩统计量,并提取其值 */
proc lifetest data=temp;
time U * event(0);
strata arm;
ods output HomTests=logrank_out;
run;
/* 从logrank_out数据集中提取统计量值(如Chi-Square)并返回 */
%mend;
/* 步骤3:网格搜索寻找使统计量接近0的AF值 */
/* 注:此处为伪代码,实际需编写循环和优化逻辑 */
data grid_search;
do af = 0.5 to 3 by 0.01; /* 设定搜索范围与步长 */
stat = %logrank_stat(af); /* 调用宏 */
output;
end;
run;
/* 找到使abs(stat)最小的af值 */
```
**更稳健的做法**是使用专门开发的SAS宏,例如由MRC临床试验单位或其它学术机构发布的经过验证的RPSFTM宏程序。
### R语言实现
R语言中有现成的软件包可以更方便地实现RPSFTM,例如 **`rpsftm`** 包。
```r
# 安装并加载包
# install.packages("rpsftm") # 如果未安装
library(rpsftm)
library(survival)
# 步骤1:准备数据框 (df)
# df 应包含以下变量:
# - id: 患者ID
# - randarm: 随机分组因子 (0=对照, 1=试验)
# - survtime: 观察到的生存时间
# - censind: 事件指示符 (1=事件,0=删失)
# - tswitch: 交叉时间(对照组患者交叉到试验组的时间,无交叉则为Inf或NA)
# - prop: 指示从随机化开始即接受试验治疗的比例(试验组=1,对照组在交叉前=0,交叉后=1)
# 步骤2:拟合RPSFTM模型
# 关键参数:
# - formula: 生存时间与事件的关系
# - censor_time: 删失时间变量
# - tx_name: 指示实际接受试验治疗的变量(根据tswitch计算)
# - arm_name: 随机分组变量
# - treat_name: 反事实治疗变量(用于g-estimation的内部构造)
# 假设我们已创建变量 `prop` 和 `eventtime` (与survtime相同,除非有特殊删失)
fit <- rpsftm::rpsftm(
formula = Surv(eventtime, censind) ~ randarm,
censor_time = rep(Inf, nrow(df)), # 假设无独立删失,或提供具体时间
data = df,
tx_name = "prop", # 实际接受试验治疗的时间比例变量
arm_name = "randarm",
treat_name = "prop" # 通常与tx_name相同
)
# 步骤3:查看模型摘要
summary(fit)
# 输出将包含加速因子(psi)的估计值及其置信区间。
# psi 即 AF,exp(psi) 有时被直接解释为加速因子。
# 步骤4:绘制反事实生存曲线
plot(fit)
# 此图将显示调整后的生存曲线(基于反事实时间U)。
# 步骤5:进行重新删失(Re-censoring)以处理因转换导致的非信息性删失
# rpsftm 包在内部可能处理了重新删失。需检查文档并报告是否应用了此步骤。
```
## 实施与报告的关键要点
根据指南,在应用和报告RPSFTM时,必须包括以下内容[1]:
1. **阐明并证明结构模型**(如“按实际治疗”或“曾接受治疗”模型)。
2. **说明用于G-估计的度量**(如对数秩检验),以及调整的基线变量(如适用)。
3. **说明使用的网格搜索算法**。
4. **绘制G-估计结果图**,以展示估计过程良好。
5. **呈现估计的加速因子及其置信区间**。
6. **在Kaplan-Meier图中比较随机组间的反事实生存时间**。
7. **详述最终结果模型**,包括计算治疗效应置信区间的方法(如保留ITT P值、自助法)以及调整的基线变量。
8. **呈现应用和未应用重新删失的结果**。
## 重要注意事项
* **共同治疗效应假设**:RPSFTM的核心假设可能不成立(例如,治疗效应可能因交叉时间、患者特征而异),需通过敏感性分析评估其影响。
* **重新删失**:当反事实时间 *U* 可能长于观察到的删失时间时,需要进行复杂的重新删失处理,以避免偏倚。`rpsftm` 包应能处理此问题,但需明确报告。
* **软件与版本**:上述代码为示例框架。实际分析应使用经过验证的、最新版本的统计包或宏,并由经验丰富的生物统计学家执行。
* **预定义分析计划**:所有调整方法,包括RPSFTM,都应在试验的统计分析计划中预先规定。
---
*本回答提供的代码框架基于公开的统计方法学原理及软件包文档,旨在指导方法学应用。实际临床试验数据分析需由专业的生物统计学家在完整的试验数据基础上完成,并严格遵守预定的分析计划。*
两阶段估计法 (TSE) 与增强两阶段估计法 (ATSE) 在估计总生存期疗效时的模拟研究比较与统计性能评估
## 研究概述
根据检索到的文献,一项发表于 *Statistical Methods in Medical Research* 的模拟研究系统比较了**两阶段估计法(TSE)** 与**增强两阶段估计法(ATSE)** 在处理肿瘤学随机对照试验(RCT)中治疗转换(Treatment Switching)偏倚时的统计性能[1]。该研究旨在评估当RCT内部对照组样本量有限且转换率高时,利用外部数据(RWD)提升疗效估计精度的潜力。
## 模拟研究设计
**研究类型**:基于蒙特卡洛模拟的统计方法学比较研究[1]。
**核心比较方法**:
1. **Oracle分析**:在模拟转换发生前的ITT分析,代表“金标准”。
2. **ITT分析**:标准意向性治疗分析(存在偏倚)。
3. **TSE**:仅基于RCT内部数据的标准两阶段估计法。
4. **ECA**:完全使用外部数据作为对照臂,忽略RCT对照组。
5. **ATSE**:使用**混合非转换臂**(Hybrid Non-Switching Arm),即结合RCT内未转换的对照组患者与外部数据。研究测试了不同衰减因子(c = 1, 4, 8),以控制外部数据的借用强度(c值越小,借用越多)[1]。
6. **ATSE(调整TTP)**:在ATSE模型中将至疾病进展时间(TTP)作为协变量进行调整。
**模拟场景**:研究设置了16个场景,变量包括:
* **治疗效应**:低(风险比HR ~0.8) vs. 高(HR ~0.5)。
* **转换比例**:中等(~40%) vs. 高(~70%)。
* **外部数据样本量**:小(N_EC = 200) vs. 大(N_EC = 1000)。
* **数据完整性**:
* **条件A(完整)**:所有混杂变量(X₁, X₂)均已测量并调整。
* **条件B(X₂不完整)**:存在影响试验参与状态(S)和预后的未测量混杂(X₂),模拟外部数据存在混杂偏倚。
* **条件C(X₁不完整)**:存在影响转换决策(W)和预后的未测量混杂(X₁),模拟TSE调整存在混杂偏倚[1]。
**主要结局指标**:限制性平均生存时间(RMST)的百分比偏倚(Percent Bias)、经验标准误(Empirical SE)和均方根误差(RMSE)。
## 统计性能比较结果
以下表格汇总了在关键场景下,TSE与ATSE(c=4)相对于Oracle分析的性能表现[1]:
| 场景与条件 | 方法 | RMST百分比偏倚 (%) | 经验标准误 (% of True RMST) | 均方根误差 (% of True RMST) | 性能评价 |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **场景1:低治疗效应,中等转换,小外部数据 (N_EC=200)** | | | | | |
| 条件A(完整) | TSE | 0.5 | 7.6 | 7.6 | 无偏,但精度较低(SE高) |
| | **ATSE (c=4)** | **0.2** | **5.8** | **5.8** | **无偏,精度显著优于TSE** |
| 条件B(外部数据有混杂) | TSE | 0.5 | 7.6 | 7.6 | 保持无偏(未使用外部数据) |
| | **ATSE (c=4)** | **1.4** | **5.8** | **6.0** | **引入轻微偏倚,但精度仍高** |
| 条件C(转换调整有混杂) | TSE | 2.1 | 7.2 | 7.5 | 出现偏倚 |
| | **ATSE (c=4)** | **1.2** | **5.9** | **6.0** | **偏倚小于TSE,精度更高** |
| **场景4:高治疗效应,高转换,小外部数据 (N_EC=200)** | | | | | |
| 条件A(完整) | TSE | 0.1 | 9.1 | 9.1 | 无偏,但精度差(高转换导致SE很高) |
| | **ATSE (c=4)** | **0.1** | **6.0** | **6.0** | **无偏,精度大幅提升** |
| **场景9:低治疗效应,中等转换,大外部数据 (N_EC=1000)** | | | | | |
| 条件A(完整) | TSE | 0.1 | 7.4 | 7.4 | 无偏,精度低 |
| | **ATSE (c=4)** | **-0.0** | **4.8** | **4.8** | **无偏,精度接近ECA且更优** |
| | ECA | 0.0 | 2.8 | 2.8 | 无偏,精度最高(但完全依赖外部数据) |
| 条件B(外部数据有混杂) | TSE | 0.1 | 7.4 | 7.4 | 保持无偏 |
| | **ATSE (c=4)** | **1.6** | **4.8** | **5.0** | **偏倚可控,精度显著优于TSE** |
| | ECA | 5.2 | 2.9 | 6.0 | **偏倚严重** |
## 关键结论与临床意义
1. **精度提升**:在**样本量有限(N_EC=200)或转换率高**的场景下,ATSE通过借用外部数据,能**显著降低疗效估计的标准误(提升精度)**,其表现 consistently 优于仅使用内部数据的TSE[1]。当外部数据量大(N_EC=1000)且无混杂时,ECA精度最高,但ATSE精度与之接近且更稳健。
2. **偏倚-精度权衡**:
* 当**外部数据存在未测混杂(条件B)** 时,ECA方法会产生严重偏倚(如偏倚达5.2%),而ATSE引入的偏倚小得多(约1.5%),同时保持了较高的精度[1]。**衰减因子(c)** 在此起到关键作用:c值越大(借用越少),来自外部数据的偏倚风险越小,但精度增益也越小。
* 当**TSE调整本身存在未测混杂(条件C)** 时,TSE会出现偏倚,而ATSE通过借用外部数据,有时能部分抵消这种偏倚,表现出更优的偏倚控制。
3. **调整TTP的作用**:在ATSE模型中加入**TTP作为协变量**,可进一步减少因未测混杂导致的偏倚,尤其在外部队列存在混杂时效果明显,代价是标准误略有增加[1]。
4. **方法选择框架**:研究提出了一个决策框架(见原文图10)[1]:
* 若**治疗转换调整的假设可疑**(如无法确保测量所有影响转换和预后的变量),则ECA可能优于ATSE。
* 若**外部数据的可交换性假设可疑**(如外部人群与试验人群差异大),则应优先选择TSE。
* 若**所有假设都难以满足**,则尽管有偏,ITT分析可能是最合适的。
## 局限性
该模拟研究基于治疗转换仅发生在疾病进展时的简化假设,未探讨时间依赖性混杂等复杂情况[1]。此外,ATSE的成功依赖于能否获得全面、高质量的协变量数据(X₁, X₂)以满足**无未测混杂**和**数据可交换性**的强假设。
## 总结
对于存在治疗转换的肿瘤学RCT,当内部对照组样本量小或转换率高导致TSE估计不精确时,**ATSE是一种有前景的增强方法**。它在借用外部数据提升精度的同时,通过动态加权(衰减因子)和纳入TTP调整,能比完全依赖外部数据的ECA方法更好地控制混杂偏倚。然而,其应用必须基于对底层假设的严格评估,并在统计分析计划中预先规定,同时辅以广泛的敏感性分析。
---
*本分析基于检索到的模拟研究文献,展示了不同统计方法在理想及存在混杂条件下的性能。实际临床试验中方法的选择需结合具体数据特征、假设的可验证性及监管要求审慎决定。*